Avantages
d'une base de données relationnelle (SGBDR)
Les bases
de données relationnelles ont été inventées en 1970 par CODD. La première a été
Ingres. Les premiers systèmes commerciaux sont apparus au début des années 80.
Cela fait donc plus de 20 ans que l'industrie et la Haute technologie utilisent
et améliorent ces systèmes qui sont maintenant largement à maturité. Les plus
connues sont SYBASE, ORACLE, INFORMIX, DB2, SQL SERVEUR.
Les plus
utilisés sur Internet sont SQL SERVER et ORACLE. Elles bénéficient d'un support
clairement identifié. Leurs avantages sont surtout évalués en terme de performances,
d'intégrité des données. Elles possèdent des systèmes évolués de sauvegarde et
de vérifications de cohérences. Ces bases sont prévues pour les systèmes d'informations
compliqués nécessitant de hauts rendements. Voici
une explication en détail avec des exemples simples.
Contrainte d'Intégrité
Référentielle (CIF) entre deux relations
Un département
est identifié par son id_departement et possède un nom. Un employé est identifié
par son id_employe, appartient à un département, possède un nom, une adresse et
une fonction. Un employé appartient à un et un seul département, un département
contient de 0 à n employés.
D'où le
Modèle Conceptuel de Donnée (MCD)
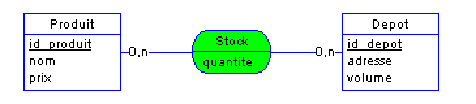
Il
entraîne le MLDR (Modèle Logique) suivant
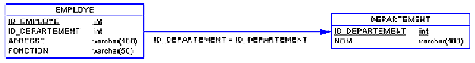
Ces deux
entités sont liées par une CIF. On ne peut créer un Employé si le Département
lui correspondant n'a pas été créé. De même, on ne peut supprimer un département
qui contient encore des employés. L'utilisation d'une base de donnée relationnelle
permet dans ce cas de confier les vérifications correspondantes à la base elle-même.
Sinon, il faut bien se rappeler de le faire tout le temps à la main dans chaque
partie du programme qui aura à créer, à supprimer ou à modifier un employé ou
un département, au risque d'avoir des données aberrantes.
Clés primaires multiples
Un produit est unique, il a un nom et un prix. Pareil pour le dépôt. Un produit
peut être dans 0 ou n dépôt. Un dépôt contient 0 ou n produits.
D'où le Modèle Conceptuel de Donnée (MCD)

Qui entraîne
le MLDR (Modèle Logique)
Produit
(id_produit, nom, prix)
Depot (id_depot, adresse, volume)
Stock
(#id_produit, #id_depot, quantité)
Le modèle
physique ainsi généré est
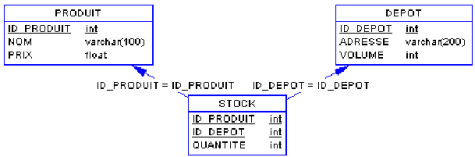
La table
Stock sert à savoir combien il y a de produits par dépôt. Chaque enregistrement
de Stock est caractérisé par une association produit/dépôt. Cette association
DOIT être unique, la clé primaire étant ici la concaténation des deux clés étrangères.
Une base de données relationnelle permettra de mettre une telle contrainte, et
d'empêcher toute duplication. Elle permettra aussi d'interdire automatiquement
la suppression d'un dépôt ou d'un produit utilisé dans Stock (CIF). Sinon, il
faudra, lors de chaque insertion, aller vérifier manuellement que l'association
produit/dépôt que l'on rajoute n'est pas déjà présente dans la table. De même,
lors de chaque suppression d'un produit ou d'un dépôt, il faudra vérifier dans
chaque partie correspondante du programme que ce produit ou que ce dépôt n'est
pas utilisé dans Stock, au risque d'avoir des données aberrantes.
Procédures stockées
Une procédure
stockée est un ensemble d'instructions SQL qui s'exécute à la demande. On peut
lui passer des paramètres et elle peut retourner un résultat au programme. Une
procédure stockée est compilée au sein même du moteur de base de donnée : elle
s'exécute toujours plus rapidement qu'un script PHP. Lors de leur exécution, un
seul échange se produit avec la base, lors de l'appel de la procédure et de la
récupération de son résultat, alors que l'exécution de chaque commande SQL en
nécessite plusieurs. Dès que plusieurs requêtes doivent s'enchaîner, l'emploi
de procédures stockées est toujours préférable au SQL dynamique. Dans le cas d'une
séparation du serveur de base de donnée du serveur frontal, elles permettent aussi
de diminuer le trafic réseau entre les deux machines.
Triggers
Un Trigger
est un ensemble d'instructions SQL appelé aussi procédure dont l'exécution est
liée à un événement dans la base de donnée. Cet événement peut être une insertion,
un enregistrement ou une modification.
Le trigger peut être lancé par la base avant l'événement, ou après. Lors d'une
suppression, cela permet par exemple d'aller automatiquement supprimer les clefs
correspondantes là où elles sont utilisées. Lors d'un ajout ou d'une modification,
cela permet d'AUTOMATISER toutes les mises à jours qui en découlent. Sinon, à
chaque fois, lors de chaque écriture d'une insertion, modification ou suppression
dans la base, programmer à la main toutes les conséquences de cet événement, sous
peine d'avoir des données aberrantes à la moindre petite erreur.
Transactions
Une transaction
est un ensemble d'actions permettant de prendre une base donnée dans un état cohérent
et de la rendre dans un état cohérent. Il s'agit d'éviter par exemple que l'on
puisse lire une information que l'on est en train de modifier par ailleurs ou
de mettre à jour, ou même que deux utilisateurs mettent à jour simultanément la
même information.
Chaque transaction se termine par un COMMIT si la transaction a réussi, ou par
un ROLLBACK qui la ramène à l'état initial si la transaction échoue pour une raison
ou pour une autre. Une transaction est en fait un comportement atomique d'une
séquence d'action (elle s'effectue avec succès ou elle est annulée).
L'exemple le plus répandu est celui du magasin : le magasinier reçoit ses livraisons,
et remplis la base. La caissière passe les codes bars, et vide la base. Le chef
de rayon modifie ses marges, fixe ses prix, et consulte ses statistiques. Si les
trois font cela simultanément sur les même données, la base sera corrompue et
aberrante dans l'heure qui suivra : les données seront fausses, et les informations
affichés à l'écran n'auront aucunes significations car entre la lecture et la
réécriture, elles auront changé.
Un des avantages de la transaction est que si une transaction s'exécute toute
seule, dans une base de données cohérente, alors elle va laisser la base de données
dans un état cohérent.